第一章 CiteSpace数据分析软件
一、软件功能简介
CiteSpace是一款可视化文献分析软件,能够以数据库中检索出的文献为基础,能够显示一个学科或知识域在一定时期发展的趋势与动向,形成若干研究前沿领域的演进历程。对科研人员研究可以提供有力的帮助。CiteSpace可以使用web of science、cnki等数据库。

独到之处在于用CiteSpaceⅡ绘制的一幅知识图谱能够显示一个学科或知识域在一定时期发展的趋势和动向,形成若干研究前沿领域的演进历程,使研究者较为容易地对科学领域进行定量和定性的研究。
软件系统基础:Java 8, 32-bit;操作系统:WINDOWS 7及以上。
二.操作流程简介
点击StartCiteSpace.bat,打开CiteSpace。然后就可以看到如下较为‘原生态’的界面。
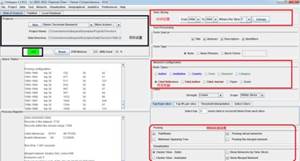
CiteSpace自身带了一个example,就是Terrorism。我现在需要新建一个Project,来建立自己的主题项目。先点上图的1,“New”,进入下图界面。
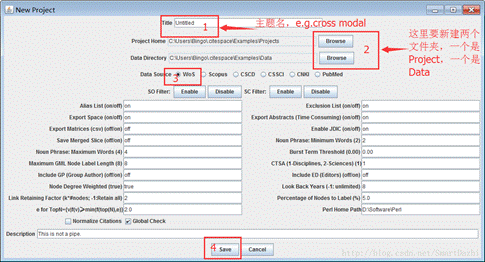
上图的2,需要分别建立两个文件夹,一个空文件是Project,另一个Data。这里简要说一下这两个文件夹的作用,Project文件夹是用来保存分析的结果,不需要添加其他内容。Data文件是存放将要被分析的数据,这个需要我们去检索,下载,然后放到这个文件夹,具体找什么如下图。
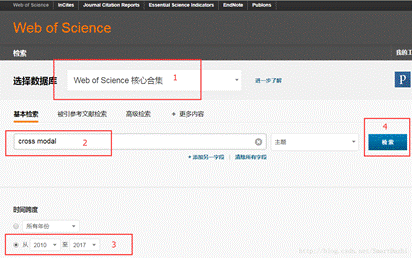
首先找cross modal主题2010-2017年的所有论文。
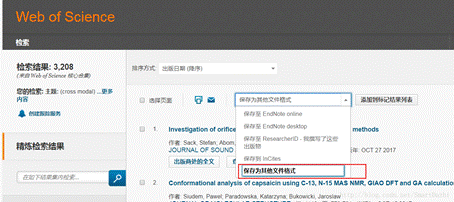
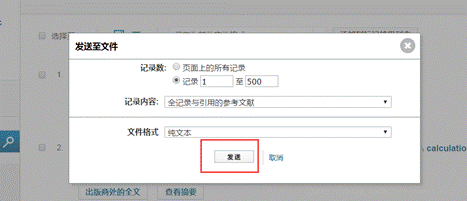
在上两个图可以知,检索结果有3208篇论文,我们现在要做的是将所有记录信息下载下来,由于Web of Science限制每次只能下载500条记录,故要多次下载,每次变化的是记录范围1至500,501至1000,1001至1500…,将每次下载的文件改名为download_xxx.txt(这是因为CiteSpace只识别以download_为前缀的文件名)。下载后的数据文件:
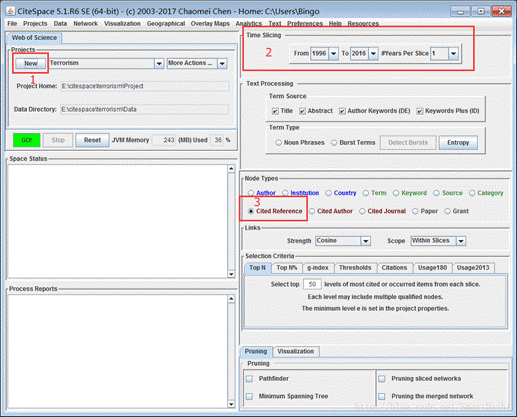
有了数据我就可以使用CiteSpace进行引用分析了,还记得最初的那个“原生态”的界面吗?就是它。

选择年份,2010-2017,时间间隔为1年。Cited Reference代表我们要选择分析的是文献引用。
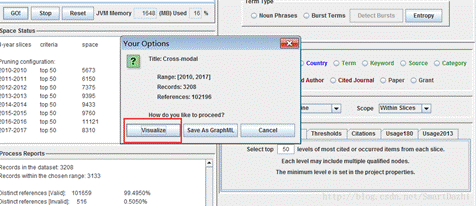
之后新出的界面就是可视化界面,背景是黑色代表正在进行迭代计算,等它计算好背景就变成白色了。
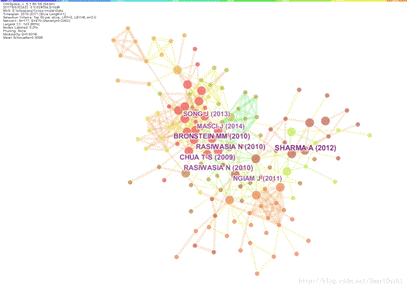
生成html报告。
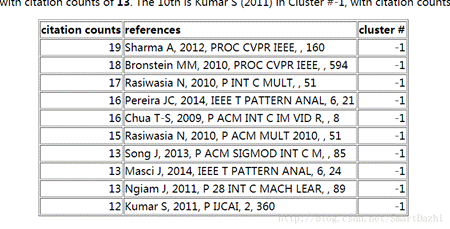
查找根据报告分析出的文献。
三、运用案例
国外科研数据管理研究进展——基于CiteSpace和VOSviewer的可视化分析.刘桂锋,李杰.图书情报研究.2016-12-18.
基于CiteSpace Ⅱ的国际太赫兹技术知识图谱研究.刘桂锋,杨国立.图书情报研究.2012-09-18.
第二章 NVivo计算机辅助定性分析软件
1.软件功能简介:NVivo是一款支持定性研究方法和混合研究方法的软件,它可帮助您管理、定型和分析几乎所有类型的数据,如Word文档、PDF、音频文件、数据库表格、电子表格、视频、图片及Web内容;且可在NVivo和其他应用程序之间交换信息,如Microsoft Word和Excel、IBM SPSS Statistics等;借助NVivo,您可以使用图表、结构图及模型等可视化工具来展示发现信息关联、洞察分析信息内涵,且可轻松查看其背后的实时数据。
2.操作流程简介:
导入材料来源(包含期刊论文、会谈记录、音频/视频记录、图片、网页或社交媒体内容等)

创建节点及编码(节点代表课题、主题、概念、建议或经验,如您可以创建水质节点,在您探查文档、PDF、数据集、音频、视频或图片等材料来源时,您可以在节点处对水质的所有参考点进行编码)
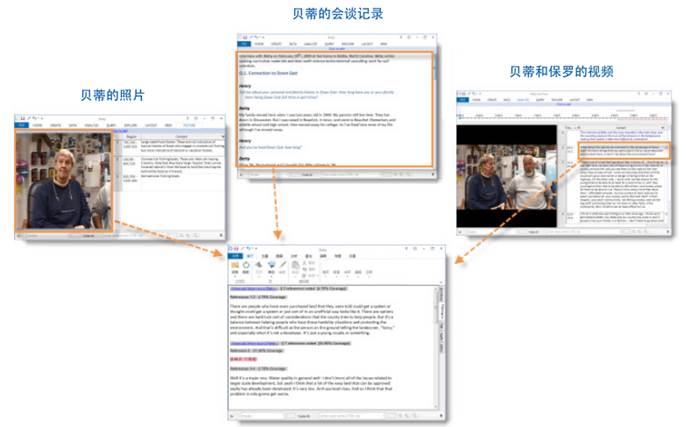
水质节点及其编码
创建查询分析(使用文本查询或词频查询可发掘材料来源中的文本信息)
文本查询:搜索来源材料中的某个词或短语并在预览节点中查看所有匹配项;
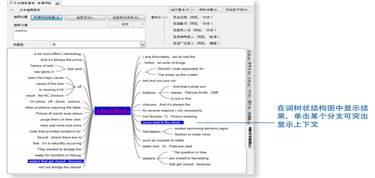
词频查询:列出在材料来源中出现频率最高的词并在单词云、树状结构图或聚类分析示意图中可视化结果

可视化分析(使用探索选项卡上的选项创建图表、导图和示意图等进行数据的可视化分析)

3.运用案例简介:
以我馆硕士研究生、现就读我校管理学院博士生苏文成的《从第82届国际图联大会看世界图书馆的发展趋势》的运用研究为案例
笔者全程参与为期六天的会议议程到访30余个主分会场聆听学者报告并参与研讨,调研全部93个展点与200件海报作品,获得会议音频20段时长近11小时,图片767张,视频30段时长17分33秒及所有会议项目资料、演讲论文文本素材,使用nvivo录入源数据清洗素材后进行主观文本编码,构建国际图书馆界发展趋势概念模型。
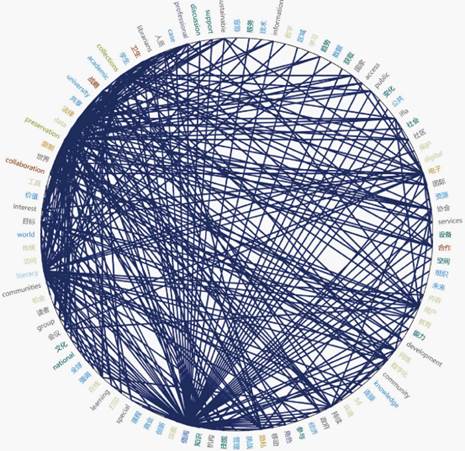
使用nvivo的词频查询功能对编码文本做关键词词频分析,绘制关键词语言云图,图中
字体大小与词频高低正相关。

关键词聚类分析
构建发展趋势概念模型

第三章 VOSviewer科学图谱的文献计量分析软件
1.软件功能简介:VOSviewer是一款基于文献的共引和共被引原理,可用于绘制各个知识领域科学图谱的文献计量分析软件。VOSviewer有两种数据导入形式可以选择:一种是text corpus(文本集),用于分析标题和摘要中词汇的共现;一种是network(网络形式),用于分析文献、期刊、作者、机构等的共引和耦合关系。
2.操作流程简介:
点击VOSviewer界面左侧Action条目下的create按钮,按照分析需求依次选择导入形式、导入WOS文本文档文件,再选择分析范围,用户可根据实际情况进行阈值设置,设置阈值后,系统会提示选择分析条目的数目,选定后系统会弹出所选条目的详细信息,确认后点击完成即可生成图谱。VOSviewer主要以四种图形方式展示:标签视图(the label view)、密度视图(the density view)、聚类密度视图(the cluster view)和散点视图(the scatter view)。
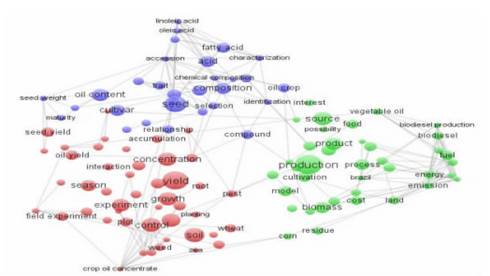 文本标签图
文本标签图
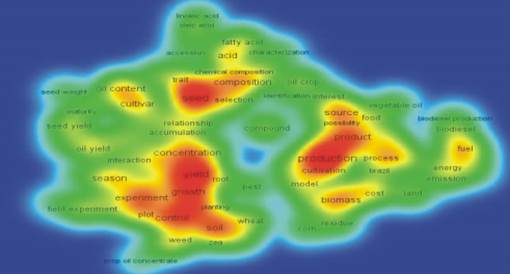 文本密度图
文本密度图
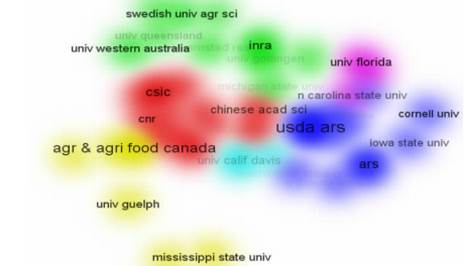 聚类密度图
聚类密度图
3.运用案例简介:
以我馆副研究馆员、硕士生导师刘桂锋博士的《国外科研数据管理研究进展——基于CiteSpace和VOSviewer的可视化分析》的运用研究为案例。
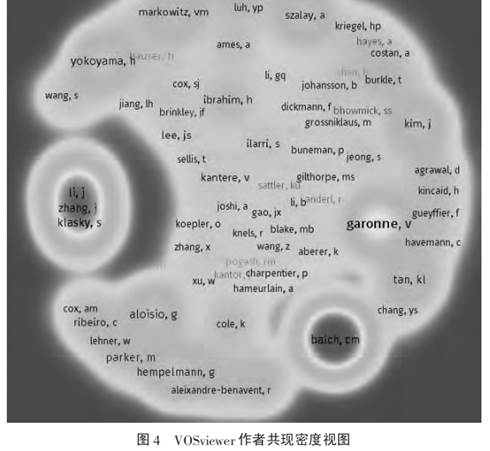
论文数据来自Web of Science(WOS)核心集中的Science Citation Index Expanded(SCI-EXPANDED)、Social Sciences Citation Index(SS-CI)、Conference Proceedings Citation Index-Science(CPCI-S)等数据库。检索式为:标题=“research data ”OR “scientific data ”OR“data management ”OR“data curation” OR“digital curation” OR “digital management”,不限时间跨度。具体对获得的2849条检索结果,其中有193条数据属于图书情报学的检索数据信息进行作者共现、文献共被引和关键词共现的VOSviewer图谱分析。


第四章 SPSS数据统计分析系统
一、软件功能简介
Statistical Product and Service Solutions,SPSS的基本功能包括数据管理、统计分析、图表分析、输出管理。SPSS统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类
SPSS是最早采用图形菜单驱动界面的统计软件,突出特点是操作界面极为友好,输出结果美观漂亮。它将所有的功能都以统一、规范的界面展现出来,使用Windows的窗口方式展示各种管理和分析数据方法的功能,对话框展示出各种功能选择项。用户只要掌握一定的Windows操作技能,精通统计分析原理,就可以使用该软件为特定的科研工作服务。SPSS采用类似EXCEL表格的方式输入与管理数据,数据接口较为通用,能方便的从其他数据库中读入数据。其统计过程包括了常用的、较为成熟的统计过程,完全可以满足非统计专业人士的工作需要。输出结果十分美观,存储时则是专用的SPO格式,可以转存为HTML格式和文本格式。对于熟悉老版本编程运行方式的用户,SPSS还特别设计了语法生成窗口,用户只需在菜单中选好各个选项,然后按“粘贴”按钮就可以自动生成标准的SPSS程序。极大地方便了中、高级用户。
SPSS for Windows的分析结果清晰、直观、易学易用,而且可以直接读取EXCEL及DBF数据文件,被称为国际上最有影响的统计软件,现已安装到我所实验室多个操作平台上。
二、操作流程简介:
1. 数据预处理
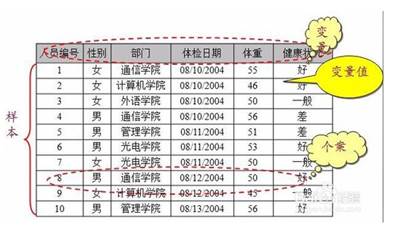
1.1. 名义尺度(Norminal)–即定类尺度,它仅仅是一种标志,用于区分变量的不同值,类别数据之间没有次序关系。例如,人口的性别、商品的名称、身份证、商店类型等。定序尺度(Ordinal)–是对事物之间等级或顺序差别的一种测度。例如,考试成绩(优、良、中、差)、人的身高等级(高、中、矮)、学历等级(博士、硕士、学士)等。间隔尺度(Scale)定距尺度(Interval),是对事物类别或次序之间间距的测度。例如,100分制考试的成绩、重量、温度等。定比尺度(Ratio),是指能够测度值之间比值的一种计量尺度。
1.2. 不同的度量尺度的统计数据在SPSS的数据文件中,对应不同的变量数据类型。➢名义尺度----数值型、字符型➢定序尺度----数值型、字符型➢间隔尺度----数值型。结构定义包括:名称、类型、宽度、小数、标签、值、缺失值、列、对齐、度量标准、角色。

1.3. 命名规则:–高版本的SPSS的变量名长度可多达64位,但是由于老版本的SPSS变量名长度应在8位之内,为了避免与老版本及其他软件出现兼容问题,变量名一般仍控制在8位之内且尽量避免中文,必要的中文说明可以放在Label栏中加以说明。–首字符应以英文字母开头,后面可以跟除了!、?、*之外的字母或数字。下划线、圆点不能为变量名的最后一个字符。–变量名必须唯一且不区分大小写字母。允许汉字作为变量名,汉字总数一般不超过4个。–变量名不能包含空格。–变量名不能与SPSS的保留字相同。SPSS的保留字包括:all、by、eq、ge、gt、leIt、ne、not、or、to、with。系统不区分变量名的大小写。


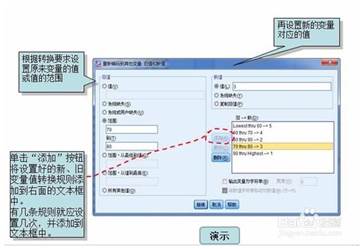
1.4. ➢变量值标签(Values)【问卷里的单选题】–变量值标签是对变量的可能取值附加的进一步说明,标签内容最多可以有120个字符,通常仅对类型或分类变量的取值指定值标签。例如,将变量Departmt定义为数值型变量时,可以按照下表中规定的值和值标签,具体定义方法见下图。

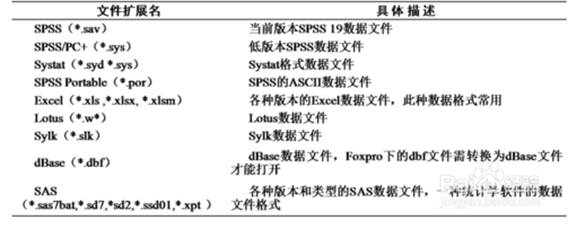
1.5. ➢选择菜单“文件→打开→数据”,弹出“打开文件”对话框左键单击“文件类型”,即可看到SPSS所能打开的数据文件类型,如下表所示:
2. 数据的纵横项合并
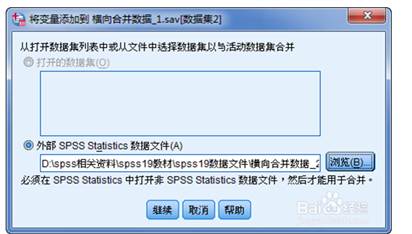
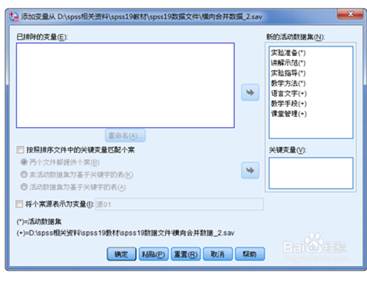
2.1. 横向合并:数据——合并文件——添加变量。单击“浏览”按钮选择要合并的SPSS数据文件的文件名。从左边文本框中选择需合并的变量到此框中。
2.2. 纵向合并:数据——合并文件——添加个案。纵向合并数据文件的操作方法同横向合并的方法类似,操作不再赘述,但需注意以下几点:两个待合并的SPSS数据文件的内容合并起来应具有实际意义;两个数据文件的结构最好一致;不同数据文件中含义相同的变量最好用相同的变量名,数据类型要相同。
3. 拆分数据
所谓的拆分并不是要把数据文件分成几个,而是根据实际情况,根据变量对数据进行分组,为以后的分组统计分析提供便利。
数据——拆分文件。

4. 数据加工
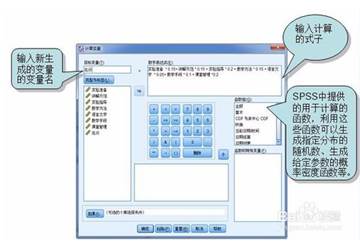
数据计算:转换——计算变量
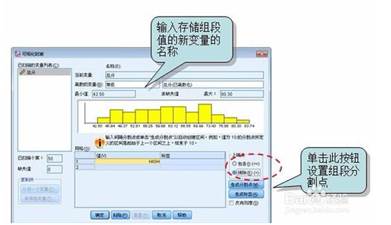
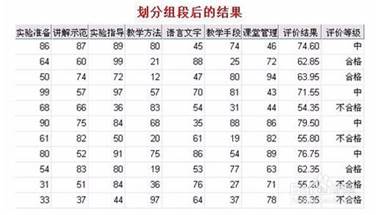
数据可视离散化。SPSS提供的数据可视离散化功能可将连续的数值型数据按由小至大的顺序加以分组(测量值由最低分至最高分分组),从而可将等距或比率变量转换为间断变量。选择“转换→可视离散化”。
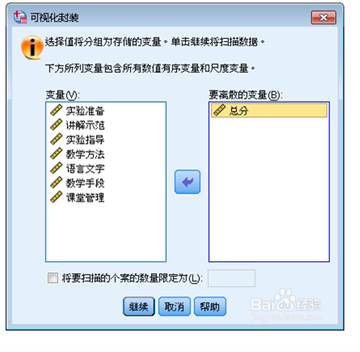

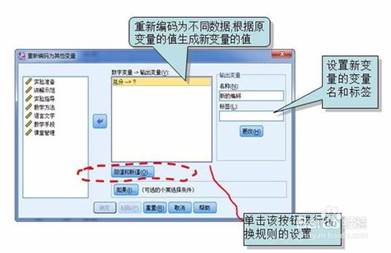
数据重新编码。转换——重新编码为不同数据。
5. 基本统计分析
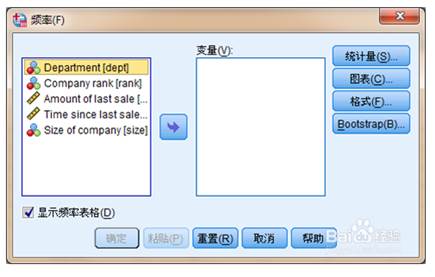
频数分析:选择菜单“分析→描述统计→频率”。1.变量选择。图的左边即为待分析的变量列表,变量选项栏用于选择要产生频数表的变量,可以同时选择多个变量。系统会分别处理。2.显示频率表格(Display Frequency Tables)选项栏。用于显示频数表。经过频率分析可以得到如下结果:(1)频率分布表:该表中包含频率、各频率占总样本数的百分比、有效百分比、累计百分比。(2)统计图:用统计图形展示变量的取值状况,频率分析中提供的统计图形可以是条形图、饼图或者直方图。
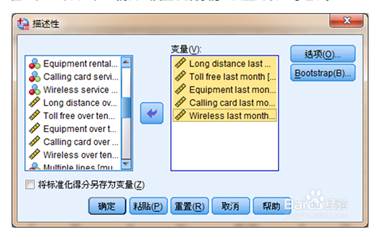
描述性分析:主要用于输出变量的各类描述性统计量的值。选择菜单“分析→描述统计→描述”,打开“描述性”主对话框,将要分析的变量加入“变量”列表框中。并勾选“将标准化得分另存为变量”。打开“描述:选项”对话框,选中“均值”、“标准差”、“最小值”、“最大值”、“峰度”、“偏度”及显示顺序的“变量列表”等选项。
探索性分析:与前面介绍的两种分析方法相比,探索性分析更加强大,它是一种在对资料的性质、分布特点等完全不清楚的情况下,对变量进行更深入研究的描述性统计方法。选择菜单“分析→描述统计→探索”,打开“探索”对话框,将“成绩”字段移入“因变量列表”,“科目”移入“因子列表”。打开“统计量”对话框,选中“描述性”;打开“探索:图”对话框,选中“按因子水平分组”、“茎叶图”、“带检验的正态图”等选项。打开“探索:选项”,选中“按列表排除个案”选项。

6. 方差分析
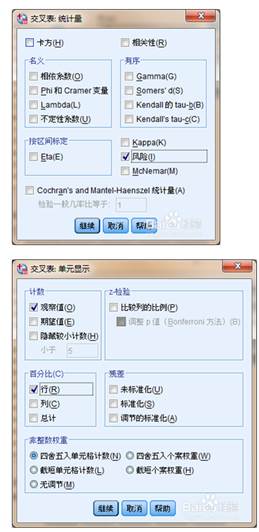
单因素方差分析:单因素方差分析(One-way ANOVA),它检验由单一因素影响的一个因变量,由因素各水平分组的均值之间的差异,是否具有统计意义,或者说它们是否来源来同一总体。选择菜单“分析→比较均值→单因素方差分析”话框,选择变量Score on training exam到“因变量列表”选项栏。选择变量Sales training group到“因子”选项栏。单击“选项”按钮则弹出如图9-4所示对话框,选中“描述性”选项栏和“方差同质性”检验选项栏,然后单击“继续”按钮返回主界面。

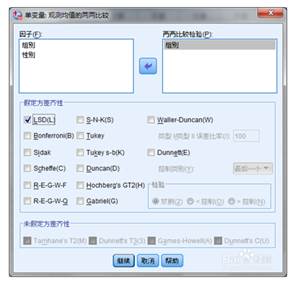
多因素方差分析:多因素方差分析用来研究两个及两个以上的控制变量是否对观测变量产生显著影响。多因素方差分析不仅能够分析多个控制因素对观测变量的影响,也能够分析多个控制因素的交互作用对观测变量产生影响,进而最终找到利于观测变量的最优组合。按“分析|一般线性模型|单变量”的步骤打开单变量对话框。并将“数学”变量移入因变量框中,将“组别”和“性别”移入固定因子中由于方差分析要求不同组别数据方差相等,故应进行方差齐性检验,单击“选项”按钮,选中“方差齐性检验”,显著性水平设为默认值0.05。单击“两两比较”按钮,如下图,在其中选出需要进行比较分析的控制变量,这里选“组别”,再选择一种方差相等时的检验模型,如LSD打开“模型”对话框,本例用默认的全因子模型。

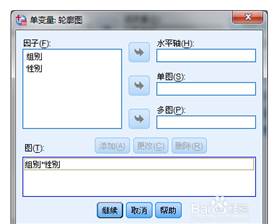
协方差分析:协方差分析是将那些很难控制的因素作为协变量,在排除协变量影响的条件下,分析控制变量对观察变量的影响,从而更加准确地对控制因素进行评价。选择菜单“分析→一般线性模型→单变量”,则弹出如图9-28所示对话框,选择变量Income after the program到“因变量”选项栏,选择变量Programstatus到“固定因子”选项栏中,选择变量Income before the program到“协变量”选项栏中。

7. 回归分析
线性回归分析:线性回归假设因变量与自变量之间为线性关系,用一定的线性回归模型来拟合因变量和自变量的数据,并通过确定模型参数来得到回归方程。作散点图,观察两个变量的相关性:依次选择菜单“图形→旧对话框→散点/点状→简单分布”,并将“国内生产总值”作为x轴,“财政收入”作为y轴,可以看出两变量具有较强的线性关系,可以用一元线性回归来拟合两变量;反之则不行选择菜单“分析→回归→线性”,打开“线性回归”对话框,将变量“财政收入”作为因变量,“国内生产总值”作为自变量。打开“统计量”对话框,选上“估计”和“模型拟合度”。
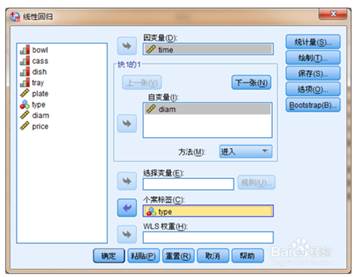
曲线估计:曲线估计(曲线拟合、曲线回归)则是研究两变量间非线性关系的一种方法,选定一种用方程表达的曲线,使得实际数据与理论数据之间的差异尽可能地小。先用散点图的形式进行分析,看究竟是否具有一元线性关系,如果具有一元线性关系,则用一元线性回归分析,否则采用曲线估计求解。进行曲线估计:依次选择菜单“分析→回归→曲线估计”,将所有模型全部选上,看哪种模型拟合效果更好(主要看决定系数R2),其所有模型的拟合优度R2如下表所示。
